Rows: 200
Columns: 11
$ id <int> 70, 121, 86, 141, 172, 113, 50, 11, 84, 48, 75, 60, 95, 104, 3…
$ gender <chr> "male", "female", "male", "male", "male", "male", "male", "mal…
$ race <chr> "white", "white", "white", "white", "white", "white", "african…
$ ses <fct> low, middle, high, high, middle, middle, middle, middle, middl…
$ schtyp <fct> public, public, public, public, public, public, public, public…
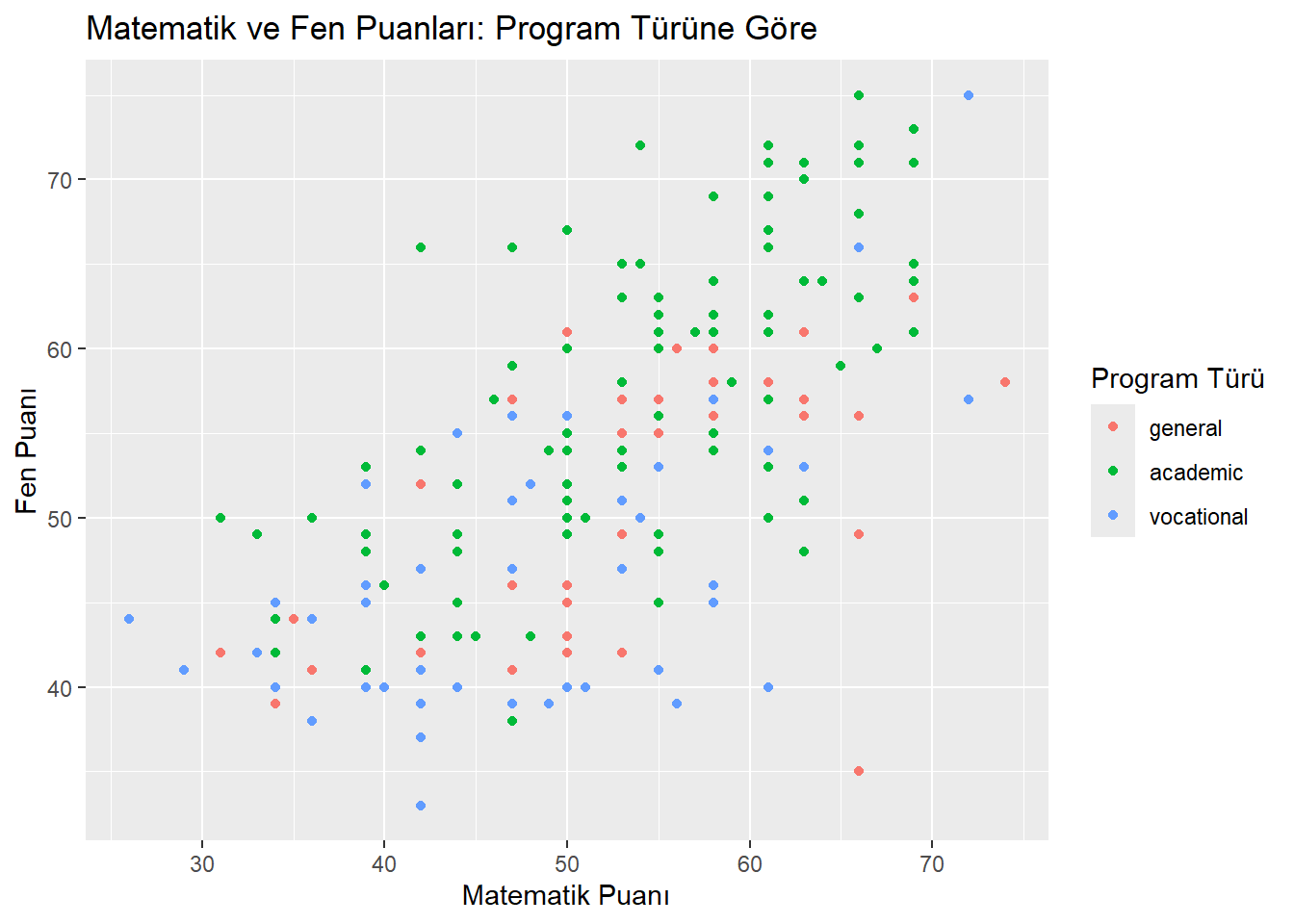
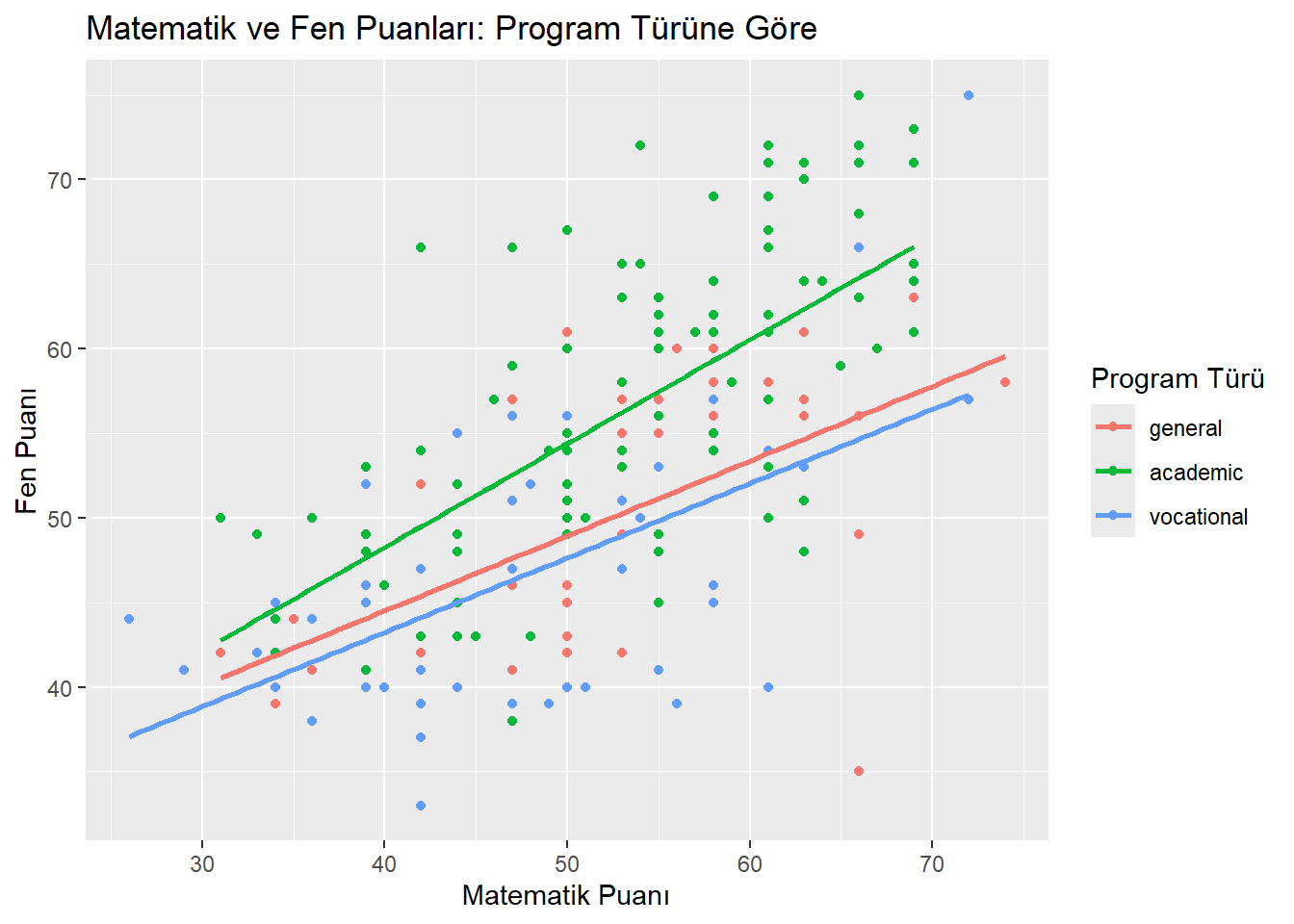
$ prog <fct> general, vocational, general, vocational, academic, academic, …
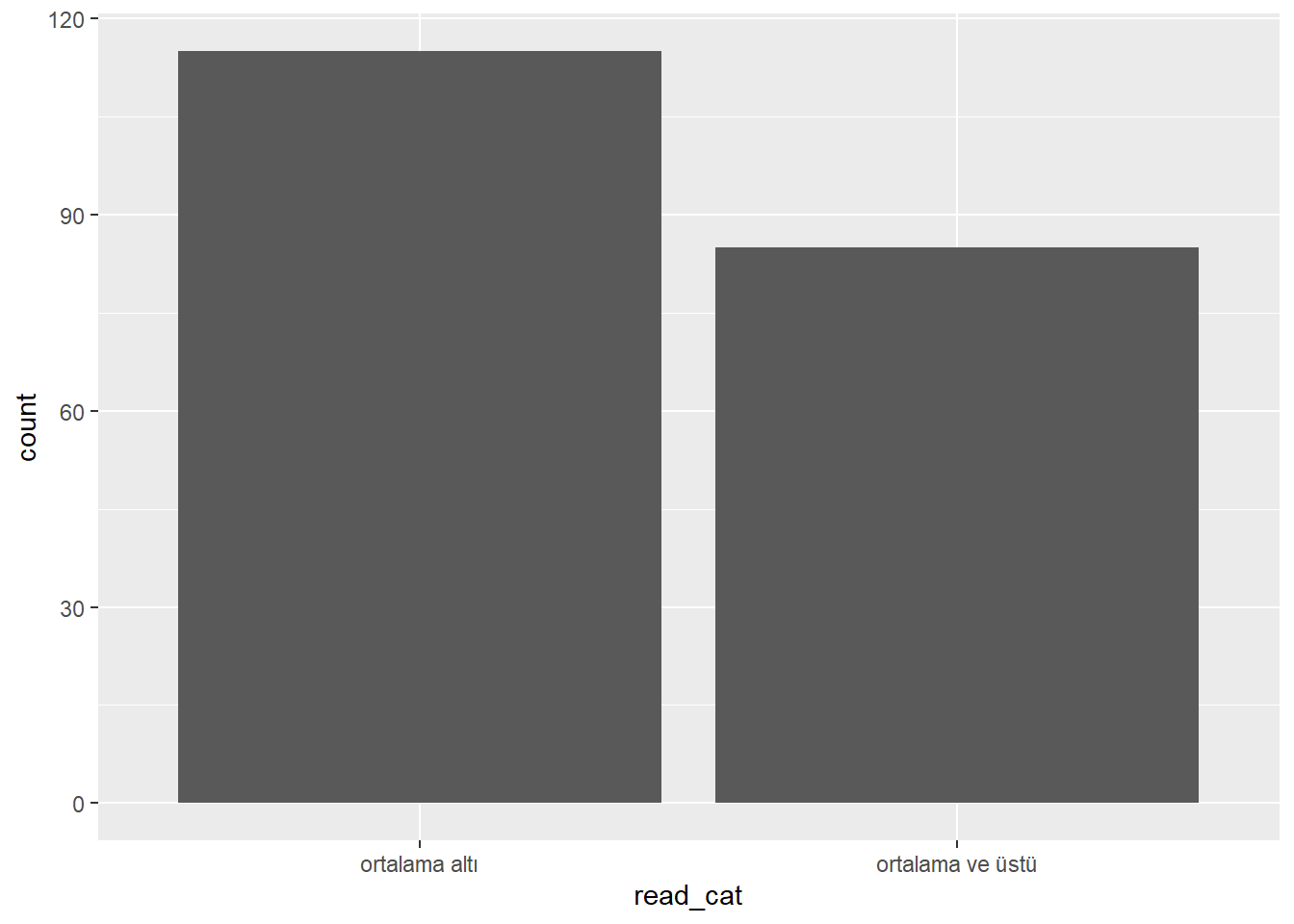
$ read <int> 57, 68, 44, 63, 47, 44, 50, 34, 63, 57, 60, 57, 73, 54, 45, 42…
$ write <int> 52, 59, 33, 44, 52, 52, 59, 46, 57, 55, 46, 65, 60, 63, 57, 49…
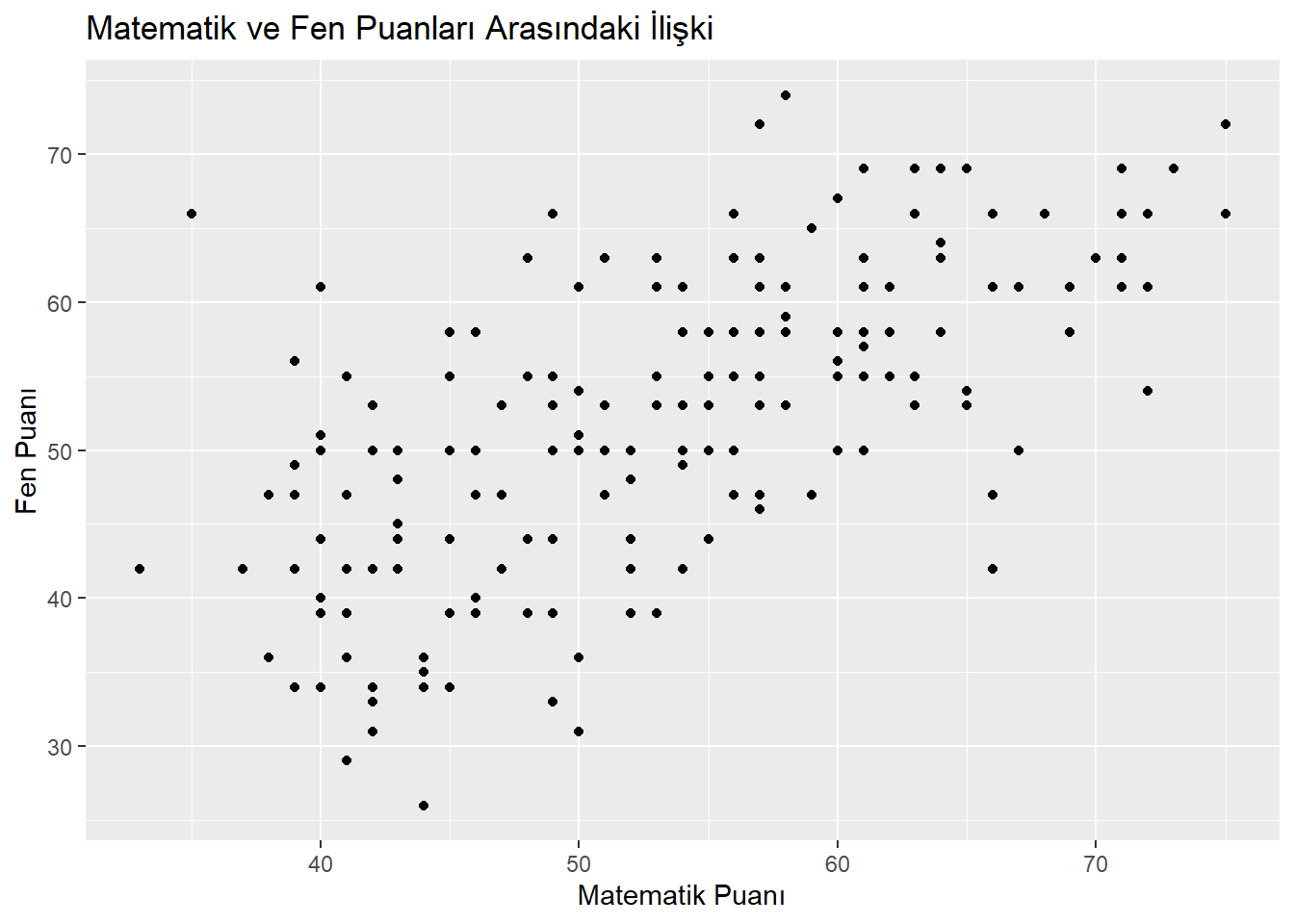
$ math <int> 41, 53, 54, 47, 57, 51, 42, 45, 54, 52, 51, 51, 71, 57, 50, 43…
$ science <int> 47, 63, 58, 53, 53, 63, 53, 39, 58, 50, 53, 63, 61, 55, 31, 50…
$ socst <int> 57, 61, 31, 56, 61, 61, 61, 36, 51, 51, 61, 61, 71, 46, 56, 56…