8 Veri Okuma ve Yazma
Veri girişi istatistiksel analiz sürecinin ilk adımıdır.
R'da veri girişi diğer yazılımlarla kıyaslandığında çok kullanışlı değildir.
Bu nedenle aktarma/import yolu tercih edilir.
Veri aktarımı için çok sayıda fonksiyon ve paket bulunmaktadır.
Ayrıca menü ile de aktarma yapılabilir.
Bilgisayardan internetten farklı formattaki veriler okunabilir.
Veri setleri genellikle Excel, SPSS veya metin dosyaları (.txt, .csv, .dat, vb.) gibi uygun veri biçimlerinde kaydedilir
R, çeşitli veri formatlarını içe aktarabilir (yani okuyabilir).
Bir veri setini R'ye aktarmanın iki yolu vardır:
- RStudio'da "Veri Kümesini İçe Aktar" menü seçeneğini kullanarak
- Belirli bir R komutunu kullanarak
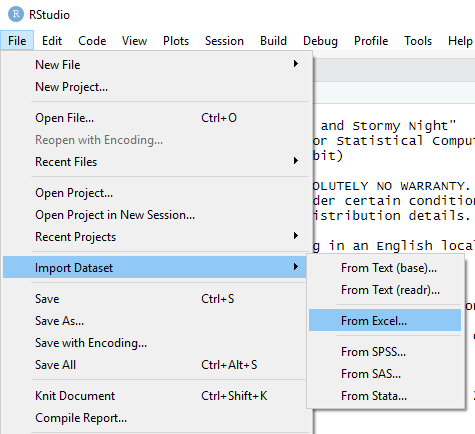
İçe aktarmak istediğiniz dosyaya göz atın.
Veri seti için bir isim verin.
İçe aktarılacak sayfayı seçin.
Değişken isimleri dosyanın ilk satırındaysa "First Row as Names".
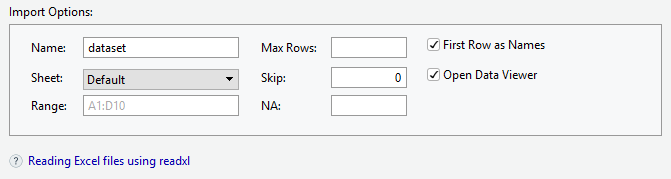
8.0.1 SPSS dosylarını içe aktarma
İçe aktarmak istediğiniz dosyaya göz atın.
Veri seti için bir isim verin.
8.1 Veri Okuma
-
En temel veri okuma/aktarma fonksiyonları
Verinin düzgün girilmiş olması okumayı kolaylaştırır.
İlk satırda genellikle değişken adlarına (header), ilk sütunda ise kimlik veya sıra numarasına yer verilir.
Gözlemlere ve değişkenlere ilişkin veri girilirken karakterler veya sayısal değerler arasında boşluk bırakmaktan kaçınmak gerekmektedir. Değişken adı boşluklu yazılmışsa ne olur?
Eksik veri boyunca aynı şekilde girilmelidir.
Değişkenlerin birinden nasıl ayrıldığı önemlidir. (, ; : / )
Tercihimiz .csv uzantılı veriler ama büyük veri setleri az yer kalması icin .txt,.prn formatında karşımıza çıkabilmektedir.
Temel pakette read.csv ve read.table gibi bazı fonksiyonlar bulunmaktadır.
Ayrıca, belirli formatlarını içe aktarmak için R paketleri bulunmaktadır.Örneğin, SPSS dosyaları için foreign ve Excel dosyaları için xlsx gibi
8.2 read.*() fonksiyonları
| Argüman | Açıklama |
|---|---|
| header | Mantıksal değerler ile verinin ilk satırında değişken isimlerinin olup olmadığını test eder. |
| sep | Sütun ayracıdır. |
| na.strings | Kayıp değerleri belirtmek için kullanılır. |
| dec | Ondalık sayıların ne ile ayrıldığını gösteren argümandır. |
| nrows | Okunmak istenilen satır sayısını belirtmek için kullanılır. |
| skip | Bir dosya okunurken okunmadan atlanmak istenilen satır sayısı için kullanılır. |
8.3 Excel dosyası aktarma
# yükle ve aktive et
install.packages("xlsx")
library("xlsx")
# read.xlsx fonksiyonunun kullanımı
my_excel_file <- read.xlsx("dizin/dosyaadi.xlsx",sheetName = "sheetname")8.3.1 SPSS dosyası aktarma
# yükle ve aktive et
install.packages("foreign")
library("foreign")
# read.spss fonksiyonunun kullanımı
my_spss_file <- read.spss("dizin/dosyaadi.sav",
to.data.frame = TRUE)8.3.2 text dosyası aktarma
- text dosyaları okumak için paket yüklemeye gerek yoktur.
# , ile ayrılmış csv dosyaları
csv_dosya <- read.csv("dizin/dosyaadi.csv",header = TRUE)
# tab ile ayrılmış txt dosyaları
txt_dosya <- read.table("dizin/dosyaadi.txt",header = TRUE, sep = "\t")Dikkat
header = TRUEsep="\t"sep=","for comma-separated files
8.4 Uygulama
- 🔗Dosyaları buradan klasör halinde indirebilirsiniz. DOSYALAR
8.4.1 txt uzantılı dosya okuma
| no | m_1 | m_2 | m_3 | m_4 | m_5 |
|---|---|---|---|---|---|
| 522 | 12 | 14.0 | 16 | 20.0 | 10 |
| 222 | 5 | NA | 20 | 10.0 | 10 |
| 454 | 5 | 10.2 | 6 | 4.0 | 10 |
| 567 | 10 | 20.0 | NA | 12.2 | 20 |
8.4.2 csv uzantılı dosya okuma
| no | m_1 | m_2 | m_3 | m_4 | m_5 |
|---|---|---|---|---|---|
| 522 | 12 | 14.0 | 16 | 20.0 | 10 |
| 222 | 5 | NA | 20 | 10.0 | 10 |
| 454 | 5 | 10.2 | 6 | 4.0 | 10 |
| 567 | 10 | 20.0 | NA | 12.2 | 20 |
- dosya okurken yeniden isimlendirme
| No | M1 | M2 | M3 | M4 | M5 | |
|---|---|---|---|---|---|---|
| 001 | 522 | 12 | 14 | 16 | 20 | 10 |
| 002 | 222 | 5 | NA | 20 | 10 | 10 |
| 003 | 454 | 5 | 10,2 | 6 | 4 | 10 |
| 004 | 567 | 10 | 20 | NA | 12,2 | 20 |
- dosya okurken belirli bir sütunu atlama
| M1 | M2 | M3 | M4 | M5 | |
|---|---|---|---|---|---|
| 001 | 12 | 14 | 16 | 20 | 10 |
| 002 | 5 | NA | 20 | 10 | 10 |
| 003 | 5 | 10,2 | 6 | 4 | 10 |
| 004 | 10 | 20 | NA | 12,2 | 20 |
8.4.3 sütun genişliğine göre okuma
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 689 | A | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 2 | 654 | B | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 3 | 436 | A | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
- Değişkenlere isim verilmiş hali
| sira | no | kitapcik | m1 | m2 | m3 | m4 | m5 | m6 | m7 | m8 | m9 | m10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 689 | A | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 2 | 654 | B | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 3 | 436 | A | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
8.4.4 SPSS dosyası okuma
| id | bolge | puan |
|---|---|---|
| 1 | 1 | 9 |
| 2 | 1 | 8 |
| 3 | 1 | 6 |
| 4 | 1 | 8 |
| 5 | 1 | 10 |
| 6 | 1 | 4 |
## tibble [50 × 3] (S3: tbl_df/tbl/data.frame)
## $ id : num [1:50] 1 2 3 4 5 6 7 8 9 10 ...
## ..- attr(*, "format.spss")= chr "F6.2"
## $ bolge: num [1:50] 1 1 1 1 1 1 1 1 1 1 ...
## ..- attr(*, "format.spss")= chr "F6.2"
## $ puan : num [1:50] 9 8 6 8 10 4 6 5 7 7 ...
## ..- attr(*, "format.spss")= chr "F6.2"8.4.5 webden dosya okuma
## [1] -0.354517 0.561655 0.315551 3.347049 -0.122389 -0.251276 -0.517996
## [8] 1.888854 0.461254 2.237483- sütun haline getirme
## [1] " -0.354517 0.573051 -0.175230"
## [2] " 0.561655 -0.368095 1.090042"
## [3] " 0.315551 -0.577052 0.425472"
## [4] " 3.347049 1.088520 1.149353"
## [5] " -0.122389 -0.694153 -0.766538"
## [6] " -0.251276 -0.017487 -1.367410"
## [7] " -0.517996 -0.817974 -1.559255"
## [8] " 1.888854 -0.658335 1.007614"
## [9] " 0.461254 0.463916 -0.898300"
## [10] " 2.237483 1.533398 0.180512"8.5 Veri Yazma
ad <- c("Ali","Elif","Su","Deniz","Aras","Berk","Can","Ece","Efe","Arda")
boy <- c(160,165,170,155,167,162,169,158,160,164)
kilo <- c(50,55,57,50,48,65,58,62,45,47)
beden <- c("S","M","S","M","S","L","M","L","S","S")
df <- data.frame(ad, boy, kilo, beden)
df| ad | boy | kilo | beden |
|---|---|---|---|
| Ali | 160 | 50 | S |
| Elif | 165 | 55 | M |
| Su | 170 | 57 | S |
| Deniz | 155 | 50 | M |
| Aras | 167 | 48 | S |
| Berk | 162 | 65 | L |
| Can | 169 | 58 | M |
| Ece | 158 | 62 | L |
| Efe | 160 | 45 | S |
| Arda | 164 | 47 | S |
write.table(df, file="df.txt")# df dosyasi nerede, gorunumu nasil
write.table(df, file="df.txt",row.names = FALSE,col.names = FALSE)
# karakter nesnler tirnak icinde ne yapmali?
write.table(df, file="df.txt",row.names = FALSE,col.names = FALSE,quote=FALSE)yeni gözlem eklemek istiyorsaniz append argümanı kullanılabilir.
ek <- data.frame(ad=c("Ahmet","Ali"), boy=c(180,170), kilo=c(60,70),
beden=c("S","L"))
write.table(ek, "df.txt",row.names=FALSE,
col.names=FALSE,
quote=FALSE,append=TRUE)write.csv() fonksiyonu kullanılarak yazılan veri dosyaları "," ile,
write.csv2() fonksiyonu kullanılarak yazılan veri dosyaları ise ";" ile ayrılır iki fonksiyonun bir diğer farkı ise ondalık sayı ayıracıdır.
write.csv ile yazdırılan dosyaların excelde açılması
8.5.1 cat() fonksiyonu
- Döngülerde sıklıkla ekrana bilgi yazdırmak amacıyla kullanılır, ancak dosya yazdırmak amacıyla da kullanabilmektedir.
- fonksiyonlarla yapılan hesaplama çıktısı da yazabilmektedir.
- Bu nedenle bir R oturumu sırasında not alınmak istenilen bilgileri bir dosyaya yazdırmak için kullanılabilir.
cat("ogrencilerin boy ortalamasi ", mean(boy), "\n",
"ogrencilerin kilo ortalamasi", mean(kilo), "\n",
file="bilgi.txt")- ne ise yaradi?
8.6 writeLines fonksiyonu
writeLines("ogrencilerin boy ortalamasi: 163 cm\n",
"ogrencilerin kilo ortalamasi: 53.7 kg",
con="bilgi2.txt")8.7 ODEV
🔗 Linkte yer alan sayfayı inceleyiniz. Bu sayfada bir veri setini incelemeniz ve bu veri seti ile ilgili sorulara cevap vermeniz beklenemketedir.
🔗Linkte yer alan sayfada sizden iki veri setini okumanız beklenmeketdir. Bu iki veri setini okuduktan sonra da hazır kodları incelemeniz ve bu kodlar ile ilgili sorulara cevap vermeniz beklenmektedir.
☕