7 Veri Setleri
Veri setleri iki boyutludur.
R'da bir çok fonksiyonun veri setleri ile çalışmaktadır.
Veri setleri R ortamında
data.frame()fonksiyonu ile oluşturulabilir.data.frame()fonksiyonu ile aynı uzunluktaki vektörlerden bir veri seti oluşturulabilir.
ad <- c("Ali","Elif","Su","Deniz","Aras", "Berk","Can","Ece","Efe","Arda")
boy <- c(160,165,170,155,167,162, 169,158,160,164)
kilo <- c(55,55,57,50,48,65, 58,62,45,47)
beden <- c("S","M","S","M","S", "L","M","L","S","S")
beden <- factor(beden)
(df <- data.frame(ad,boy, kilo, beden))| ad | boy | kilo | beden |
|---|---|---|---|
| Ali | 160 | 55 | S |
| Elif | 165 | 55 | M |
| Su | 170 | 57 | S |
| Deniz | 155 | 50 | M |
| Aras | 167 | 48 | S |
| Berk | 162 | 65 | L |
| Can | 169 | 58 | M |
| Ece | 158 | 62 | L |
| Efe | 160 | 45 | S |
| Arda | 164 | 47 | S |
- Eğer uzunlukları farklı olan vektörlerle veri setleri oluşturulmaya çalışılırsa kısa vektör, uzun vektör uzunluğunda tekrar eder.
# 4 farklı uzunlukta vektör oluşturulması
x <- 11:14; y <- 10; M <- c(10,35); N <- 2:4
data.frame(x, y) # (4,1)| x | y |
|---|---|
| 11 | 10 |
| 12 | 10 |
| 13 | 10 |
| 14 | 10 |
data.frame(x, M) # (4,2)| x | M |
|---|---|
| 11 | 10 |
| 12 | 35 |
| 13 | 10 |
| 14 | 35 |
data.frame(x,N) #(4,3) hata## Error in data.frame(x, N): arguments imply differing number of rows: 4, 3
data.frame(y, M) #(1,2)| y | M |
|---|---|
| 10 | 10 |
| 10 | 35 |
data.frame(y, N) #(1,3)| y | N |
|---|---|
| 10 | 2 |
| 10 | 3 |
| 10 | 4 |
data.frame(M, N) #(2,3)## Error in data.frame(M, N): arguments imply differing number of rows: 2, 37.1 Hazır Veri Setleri
- Temel pakette yer alan veri setlerinin bir listesine aşağıdaki komutla ulaşabilirsiniz.
data() # yeni bir pencerede açılır.- Veri setlerinin yer aldığı paketlerde bulunmaktadır.
- Hazır veri setleri çalışma ortamına
data()fonksiyonu ile aktarılabilir.
data(WorldPhones) # environmet(calisma alanini) kontrol ediniz. - hazır veri setlerini incelememek için aşağıdaki komutlar kullanılabilir.
data(cars) # enviromente ekler
iris # enviromente eklemez!7.2 İnceleme
- Boyut sorgulamamak için farklı fonksiyonlar kullanılabilir.
dim(cars) # satir Sutun## [1] 50 2
nrow(cars)## [1] 50
ncol(cars)## [1] 2- Veri setlerin ilk satırları
head(), son satırları isetail()fonksiyonu ile incelenebilir.head()fonksiyonu olağan olarak ilk 6 satırı yazdırır.
head(WorldPhones)## N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
## 1951 45939 21574 2876 1815 1646 89 555
## 1956 60423 29990 4708 2568 2366 1411 733
## 1957 64721 32510 5230 2695 2526 1546 773
## 1958 68484 35218 6662 2845 2691 1663 836
## 1959 71799 37598 6856 3000 2868 1769 911
## 1960 76036 40341 8220 3145 3054 1905 1008- Yazdırılacak satır sayısı
nargümanı ile ayarlanır.
head(WorldPhones,n=2)## N.Amer Europe Asia S.Amer Oceania Africa Mid.Amer
## 1951 45939 21574 2876 1815 1646 89 555
## 1956 60423 29990 4708 2568 2366 1411 733WorldPhones veri setinin son 8 satırını yazdıracak kodu yazınız.
datasetspaketinde yer alan veri setlerindeexamples()bölümünde çeşitli örneklere yer verilmiştir. Örneğinexample(WorldPhones)
matplot(rownames(WorldPhones), WorldPhones, type = "b", log = "y",
xlab = "Year", ylab = "Number of telephones (1000's)")
legend("bottomright", colnames(WorldPhones), col = 1:6, lty = 1:5,
pch = rep(21, 7))
title(main = "World phones data: log scale for response")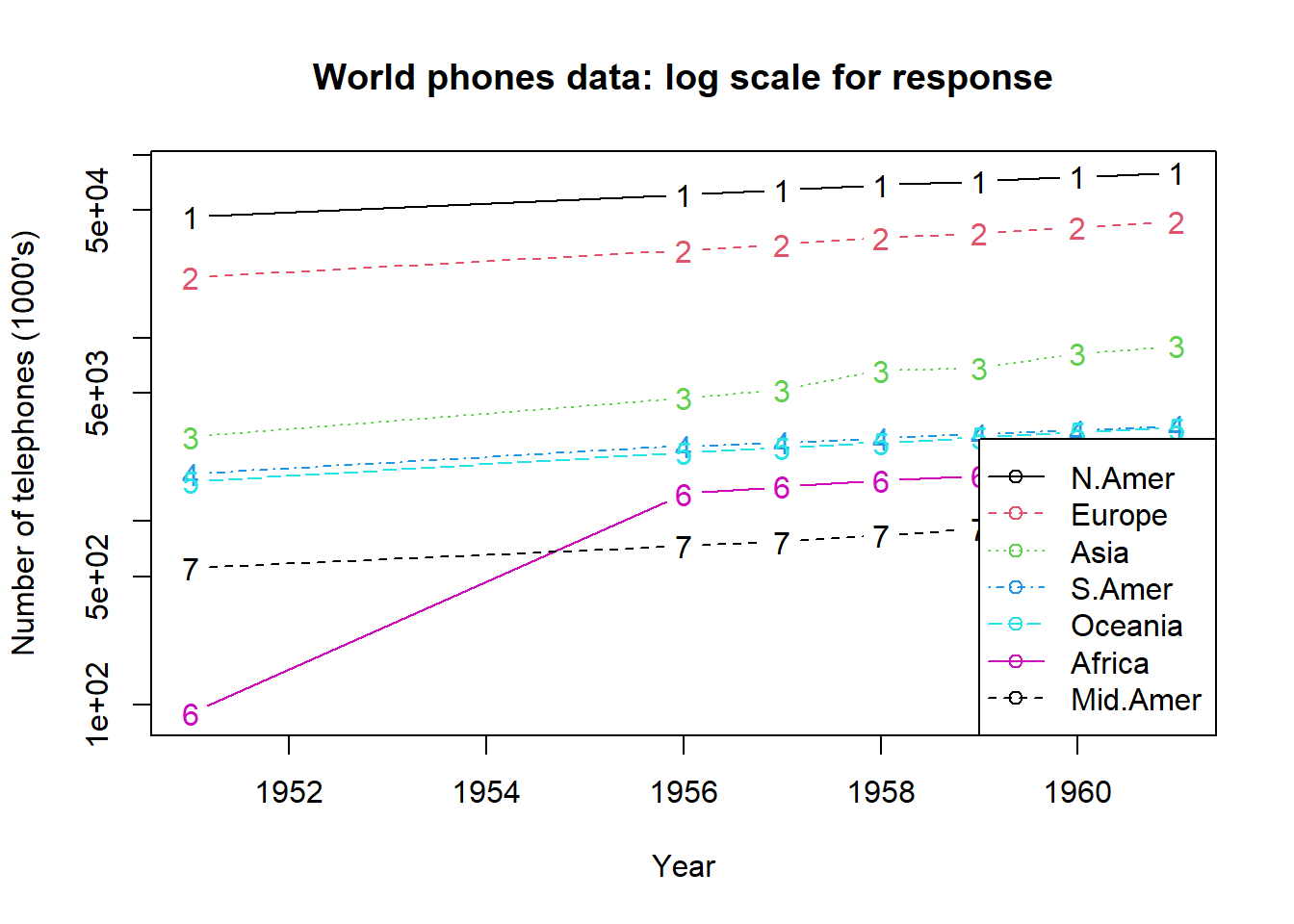
- Temel paket hariç diğer paketlerdeki veri setlerine
data(veriseti, package="packagename")şeklinde ulaşılabilir.
Kullanışlı olmasa da excel, spps gibi veri girişi sağlayan bir arayüz bulunmaktadır.
Ali, Su ve Ece'nin boylarının ve kilolarının seçilmesi
df1<- data.frame()
df1 <- edit(df1)
# duzenlemek icin
fix(df)
# gozatmak icin
View(df)7.3 Eleman Seçme
Veri setlerinde eleman seçme matrislerdeki gibidir.
df[satirindeks, sutunindeks]
- df'nin birinci satir elemanlarının seçilmesi
| ad | boy | kilo | beden |
|---|---|---|---|
| Ali | 160 | 55 | S |
- df'nin birinci sütun elemanlarının seçilmesi
## [1] "Ali" "Elif" "Su" "Deniz" "Aras" "Berk" "Can" "Ece" "Efe"
## [10] "Arda"- df'nin ikinci satır elemanlarının seçilmesi
| ad | boy | kilo | beden | |
|---|---|---|---|---|
| 2 | Elif | 165 | 55 | M |
- df'nin ikinci sütun elemanlarının seçilmesi
## [1] 160 165 170 155 167 162 169 158 160 164- df'nin birinci satır üçüncü sütun elemanlarının seçilmesi
## [1] 55- Veri setlerinde satır elemanları yazdırıldığında veri seti (
data.frame), sütun elemanları yazdırıldığında ise vektör (vector)oluşmaktadır.
# satir secimi
is.data.frame(df[1,])## [1] TRUE
# sutun secimi
is.data.frame(df[,1])## [1] FALSE- Sütun seçimi veri seti (
data.frame) olarak yapılmak istenirse,dropargümanı FALSE değeri ile kullanılır.
df[,1,drop=FALSE]| ad |
|---|
| Ali |
| Elif |
| Su |
| Deniz |
| Aras |
| Berk |
| Can |
| Ece |
| Efe |
| Arda |
Veri seçim işlemi için
subset()fonksiyonu kullanılabilir.?subsetbir fonksiyonu ilk daha kullanıyorsanız, mutlaka yardım sayfasını inceleyin.
subset(veriseti, kosul/Kosullar)
- Boyu 165cm'den uzun öğrencilerin bilgilerinin seçilmesi
subset(df, boy >165)| ad | boy | kilo | beden | |
|---|---|---|---|---|
| 3 | Su | 170 | 57 | S |
| 5 | Aras | 167 | 48 | S |
| 7 | Can | 169 | 58 | M |
-
subset()fonksiyonun yardım sayfasındaki örnekleri inceleyebilirsiniz.
| Ozone | Temp | |
|---|---|---|
| 42 | NA | 93 |
| 43 | NA | 92 |
| 69 | 97 | 92 |
| 70 | 97 | 92 |
| 75 | NA | 91 |
| 102 | NA | 92 |
| 120 | 76 | 97 |
| 121 | 118 | 94 |
| 122 | 84 | 96 |
| 123 | 85 | 94 |
| 124 | 96 | 91 |
| 125 | 78 | 92 |
| 126 | 73 | 93 |
| 127 | 91 | 93 |
subset(airquality, Day == 1, select = -Temp)| Ozone | Solar.R | Wind | Month | Day | |
|---|---|---|---|---|---|
| 1 | 41 | 190 | 7.4 | 5 | 1 |
| 32 | NA | 286 | 8.6 | 6 | 1 |
| 62 | 135 | 269 | 4.1 | 7 | 1 |
| 93 | 39 | 83 | 6.9 | 8 | 1 |
| 124 | 96 | 167 | 6.9 | 9 | 1 |
df verisinde beden değişkeni "S" olan satırların seçimi
subset(df,beden =="S")df verisinde kilosu 50'in altında olan kişilerden oluşan veri seti oluşturma kodunu tamamlayınız
subset(df,.......)
7.4 Eleman ekleme
- Veri setine yeni sütun ekleme isleme
$operatörü ile[[]]operatörü ilecbind()fonksiyonları ile yapılabilmektedir.
df2 <- data.frame(
S1 = sample(0:100,20),
S2 = runif(n=20 ,min= 50 , max=70)
)
head(df2)| S1 | S2 |
|---|---|
| 37 | 64.94345 |
| 1 | 51.91993 |
| 71 | 63.42551 |
| 77 | 53.56406 |
| 63 | 65.35272 |
| 42 | 63.27010 |
-
$operatörü ile sütun ekleme
| S1 | S2 | S3 |
|---|---|---|
| 37 | 64.94345 | 67 |
| 1 | 51.91993 | 73 |
| 71 | 63.42551 | 76 |
| 77 | 53.56406 | 77 |
| 63 | 65.35272 | 60 |
| 42 | 63.27010 | 65 |
[[]]operatörü ile sütun eklemedf2 veri setinin ilk üç sütunun
rowMeans()fonksiyonu ile ortalamasının alınarak ort isimi ile veri setine eklenmesi
| S1 | S2 | S3 | ort |
|---|---|---|---|
| 37 | 64.94345 | 67 | 56.31 |
| 1 | 51.91993 | 73 | 41.97 |
| 71 | 63.42551 | 76 | 70.14 |
| 77 | 53.56406 | 77 | 69.19 |
| 63 | 65.35272 | 60 | 62.78 |
| 42 | 63.27010 | 65 | 56.76 |
-
cbind()fonksiyonu ile sütun ekleme
cbind( df2, S4 = 10)| S1 | S2 | S3 | ort | S4 |
|---|---|---|---|---|
| 37 | 64.94345 | 67 | 56.31 | 10 |
| 1 | 51.91993 | 73 | 41.97 | 10 |
| 71 | 63.42551 | 76 | 70.14 | 10 |
| 77 | 53.56406 | 77 | 69.19 | 10 |
| 63 | 65.35272 | 60 | 62.78 | 10 |
| 42 | 63.27010 | 65 | 56.76 | 10 |
| 12 | 51.06149 | 63 | 42.02 | 10 |
| 3 | 58.37801 | 63 | 41.46 | 10 |
| 27 | 56.96972 | 60 | 47.99 | 10 |
| 28 | 52.06823 | 80 | 53.36 | 10 |
| 82 | 58.79704 | 75 | 71.93 | 10 |
| 96 | 62.87552 | 79 | 79.29 | 10 |
| 40 | 55.72831 | 80 | 58.58 | 10 |
| 0 | 58.59491 | 77 | 45.20 | 10 |
| 53 | 50.97243 | 65 | 56.32 | 10 |
| 64 | 69.71524 | 66 | 66.57 | 10 |
| 61 | 51.45924 | 73 | 61.82 | 10 |
| 21 | 59.02196 | 79 | 53.01 | 10 |
| 17 | 63.76606 | 68 | 49.59 | 10 |
| 95 | 59.59905 | 66 | 73.53 | 10 |
7.5 Eleman çıkarma
Veri setinden istenilen sütunun çıkarılabilir. Bu işlemi yapmak için iki farklı yol kullanılabilir.
-operatörü
head(df2,3)| S1 | S2 | S3 | ort |
|---|---|---|---|
| 37 | 64.94345 | 67 | 56.31 |
| 1 | 51.91993 | 73 | 41.97 |
| 71 | 63.42551 | 76 | 70.14 |
df2 <- df2[,-4]
head(df2,3)| S1 | S2 | S3 |
|---|---|---|
| 37 | 64.94345 | 67 |
| 1 | 51.91993 | 73 |
| 71 | 63.42551 | 76 |
-
NULLoperatörü
df2$S3 <- NULL
head(df2,3)| S1 | S2 |
|---|---|
| 37 | 64.94345 |
| 1 | 51.91993 |
| 71 | 63.42551 |
7.6 Satır ekleme
- Veri setlerine değişken ekleyip, çıkarabileceğiniz gibi gözlem de ekleyip, çıkarabilirsiniz. Veri setine iki satır ekleme
dim(df2)## [1] 20 2
# eklenecek iki satırlık veri seti oluşturma
df3 <- data.frame(S1=c(50,60),S2=c(55.3,65.5))
# yeni veri seti
df4 <- rbind (df2,df3)
dim(df4)## [1] 22 27.7 Veri yapısı inceleme
- Veri setlerinin yapısını incelemek icin
str()fonksiyonundan yararlanılmaktadır.
str(df)## 'data.frame': 10 obs. of 4 variables:
## $ ad : chr "Ali" "Elif" "Su" "Deniz" ...
## $ boy : num 160 165 170 155 167 162 169 158 160 164
## $ kilo : num 55 55 57 50 48 65 58 62 45 47
## $ beden: Factor w/ 3 levels "L","M","S": 3 2 3 2 3 1 2 1 3 3"df" veri seti 10 gözlemden, 4 değişken. Her bir değişkenin önünde
$operatörü olduğuna dikkat ediniz.veri setinin incelenmek için kullanılabilecek diğer fonksiyon ise
attributes()
attributes(df)## $names
## [1] "ad" "boy" "kilo" "beden"
##
## $class
## [1] "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6 7 8 9 107.8 Isimlendirme
- Veri setleri vektör birleştirme üzerinden yapılırsa, vektör adları sütun ismi olarak kullanılır. Ancak bu isimler değiştirilebilir. Bu işlem
data.frame()fonksiyonu içinde yapılabilir.
df <- data.frame(isim = ad,
boyolcum = boy,
kiloolcum= kilo,
bedenolcum=beden)
df| isim | boyolcum | kiloolcum | bedenolcum |
|---|---|---|---|
| Ali | 160 | 55 | S |
| Elif | 165 | 55 | M |
| Su | 170 | 57 | S |
| Deniz | 155 | 50 | M |
| Aras | 167 | 48 | S |
| Berk | 162 | 65 | L |
| Can | 169 | 58 | M |
| Ece | 158 | 62 | L |
| Efe | 160 | 45 | S |
| Arda | 164 | 47 | S |
- Veri seti isimlendirme de diğer bir yol ise
names()ya dacolnames()fonksiyonlarıdır.
df <- data.frame(ad,boy,kilo,beden)
names(df) <- c("isim","boyolcum ","kiloolcum","bedenolcum")
df| isim | boyolcum | kiloolcum | bedenolcum |
|---|---|---|---|
| Ali | 160 | 55 | S |
| Elif | 165 | 55 | M |
| Su | 170 | 57 | S |
| Deniz | 155 | 50 | M |
| Aras | 167 | 48 | S |
| Berk | 162 | 65 | L |
| Can | 169 | 58 | M |
| Ece | 158 | 62 | L |
| Efe | 160 | 45 | S |
| Arda | 164 | 47 | S |
7.9 Betimsel istatistikler
- Veri setinin tümüne ilişkin betimsel istatistikler
summary(cars)## speed dist
## Min. : 4.0 Min. : 2.00
## 1st Qu.:12.0 1st Qu.: 26.00
## Median :15.0 Median : 36.00
## Mean :15.4 Mean : 42.98
## 3rd Qu.:19.0 3rd Qu.: 56.00
## Max. :25.0 Max. :120.00- Veri setinin tek değişkenine ilişkin betimsel istatistikler
summary(cars$speed)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.0 12.0 15.0 15.4 19.0 25.0attach() fonksiyonu ile bir veri setinin sütunları sütun isimi ile enviromente eklenir. Aynı işlem detach() fonksiyonu ile tersine alınabilir.
summary(women$height) ## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 58.0 61.5 65.0 65.0 68.5 72.0
attach(women)
summary(height) # Ayni nesne isimi ile çağırılır.## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 58.0 61.5 65.0 65.0 68.5 72.0
height <- height*2.54 # Bunu yapmamaya calisin!!
find("height")## [1] ".GlobalEnv" "women"
summary(height) # Yeni değişken## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 147.3 156.2 165.1 165.1 174.0 182.9
rm(height)
detach("women")
summary(women$height) # unchanged## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 58.0 61.5 65.0 65.0 68.5 72.07.9.1 Kendinizi Test Edin
S1. Sırayla değişken adları TamSayi, OndalikSayi, Karakter, Mantıksal, Faktör olan 5 değişkenli hiçbir gözlemi olmayan bir data.frame oluşturmanızı ve bu data.framenin yapısını yazdırmanızı bekliyorum. Beklenen çıktı aşağıdaki gibi olmalıdır.
[1] "Bos data.framenin yapısı:"
'data.frame': 0 obs. of 5 variables:
$ TamSayi : int
$ OndalikSayi: num
$ Karakter : chr
$ Mantiksal : logi
$ Faktor : Factor w/ 0 levels:
NULLS2. Aşağıda size verilen dört vektörden bir veri seti oluşturunuz. Oluşturduğunuz veri setinin deneme sütunundaki eksik veri sayısını hesaplayan komut yazınız.
ad = c('Su','Pera','Sule','Can','Cem','Name','Aras','Mete','Kaan','Pelin')
puan = c(12.5, 9, 16.5, 12, 9, 20, 14.5, 13.5, 8, 19)
deneme = c(1, NA, 2, NA, 2, NA, 1, NA, 2, 1)
bonus = c(1,0,1, 0, 0, 1, 1, 0,0, 1)"Deneme sütunundaki NA sayısı:" [1] 4
7.10 Odev
Lütfen aşağıdaki bölümleri haftaya kadar okuyunuz.
Veri düzenleme konusunda 🔗 DataEditR paketini inceleyiniz.